从上一篇中,我们了解了强化学习的一些重要的基本概念: 马尔可夫决策过程,贝尔曼方程 等等。 为了理解Deep Q-Learning,需要先学习这些 基本概念。
Deep Q-Learning
简介
强化学习可以分为 1. 基于Value的强化学习 2. 基于Policy的强化学习 3. 基于Model的强化学习
DQN就是一个基于Value的强化学习的典型代表。该算法由Deepmind最先提出,后来发表在Nature上论文链接。
相比于Q-Learning, 应用神经网络来表示Q函数,可以解决Q-函数表太大,收敛太慢的问题。 例如DQN应用在Atari游戏中,输入是每4帧的Atari的游戏画面,通过网络后,输出为每个action的Q-Values值。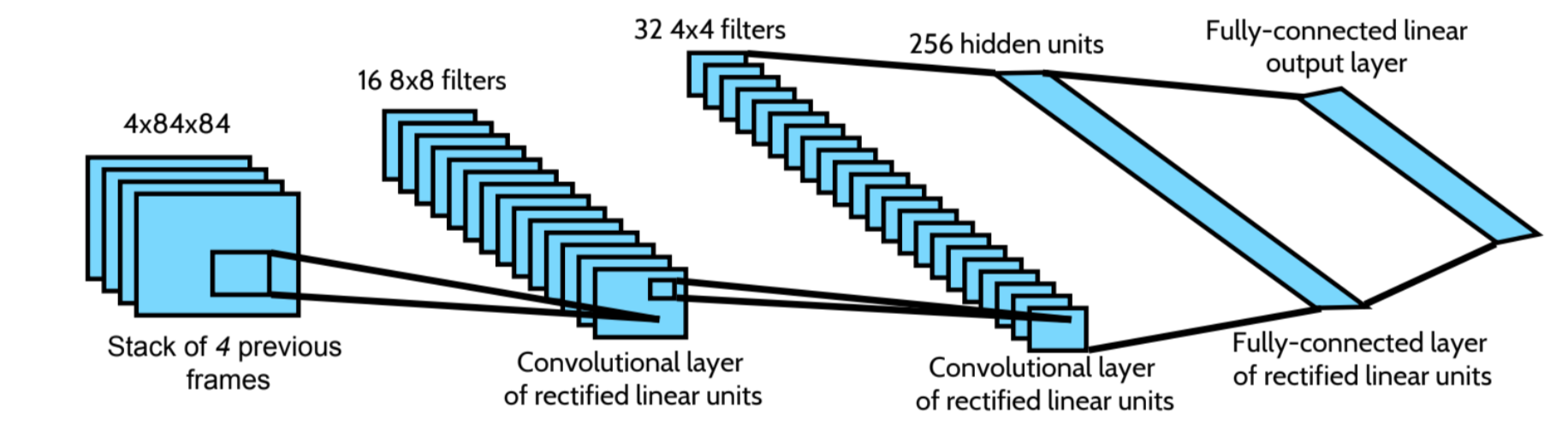
Action-Value Function
在前一篇里有动作价值函数\(Q(s,a)\)的具体介绍。简单来说,就是agent从状态\(s\)开始,采用动作\(a\),并且遵循策略\(\pi\),获得的预期回报。 \[ Q_{\pi}(s, a) = \mathbb{E} [R_{t+1} + \gamma Q_{\pi}(S_{t+1}, A_{t+1}) \vert S_t = s, A_t = a] \]
\(Q(s,a)\) 表示了智能体在状态\(s\)下采用可能的动作\(a\)得到的quality。给定状态\(s\) Action-Value函 该状态下每个可能动作\(a_i\)的标量值(quality/value)。更高的值表示当前智能体采取了更好的行动。
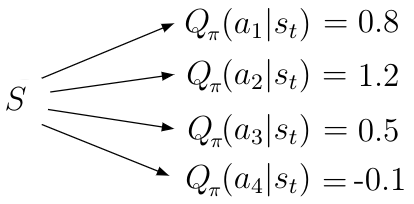
当引入状态转移矩阵后,我们可以得到上式的一个等价的新的动作价值函数: \[ Q_{\pi}(s, a) = R(s, a) + \gamma \sum_{s' \in \mathcal{S}} P_{ss'}^a \sum_{a' \in \mathcal{A}} \pi(a' \vert s') Q_{\pi} (s', a') \]
时序差分学习(Temporal Difference Learning)
与蒙特卡洛方法类似,时序差分学习也是免模型和从episodes经验中学习的方法,但是TD法可以从不完整的episodes中学习,我们无需将episode执行到\(S_T\)最终的状态。可以通过自身的Boostrapping猜测episode的结果,同时持续更新这个猜测。
基于特定策略\(\pi\) 的episode可以如前一篇所示为: \[ S_1,A_1,R_2,S_2,A_2,\dots,S_T \]
完整的episode 指必须从某一个状态(不特指起始状态)开始,agent与environment交互直到\(S_T\)状态,环境给出终止状态的即时收获为止。
Bootstrapping
TD学习方法仅针对现有估计更新目标值,而不是像蒙特卡洛方法完全依赖episodes的实际奖励和完整回报。 这种方法称为bootstrapping。
值估计
在Monte-Carlo学习中,使用实际的回报(return)\(G_{t}\)来更新价值(Value): \[ V(S_{t}) \leftarrow V(S_{t}) + \alpha (G_{t} - V(S_{t})) \] 在TD Learning中最重要的一个概念是将价值函数\(V(S_t)\)的更新变为使用 离开该状态的即刻奖励 \(R_{t+1}\) 与下一状态\(S_{t+1}\)的预估状态价值乘以衰减系数\(\gamma\)组成,即\(R_{t+1} +\gamma V(S_{t+1})\) 被称为TD target。此外我们控制更新值函数程度可以用学习率\(\alpha\)这个参数。
\[ \begin{aligned} V(S_t) &\leftarrow (1- \alpha) V(S_t) + \alpha G_t \\\\ V(S_t) &\leftarrow V(S_t) + \alpha (G_t - V(S_t)) \\\\ V(S_t) &\leftarrow V(S_t) + \alpha (R_{t+1} + \gamma V(S_{t+1}) - V(S_t)) \end{aligned} \]
式中:
\(R_{t+1} + \gamma V(S_{t+1})\) 被称为TD target
\(\delta_{t} = R_{t+1} + \gamma V(S_{t+1}) - V(S_{t})\)被称为TD error
对于动作-价值(action-value)估计来说,也有类似的: \[ Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \alpha (R_{t+1} + \gamma Q(S_{t+1}, A_{t+1}) - Q(S_t, A_t)) \]
那么如何通过TD learning(TD control)来学习最优策略?
SARSA: On-Policy TD Control
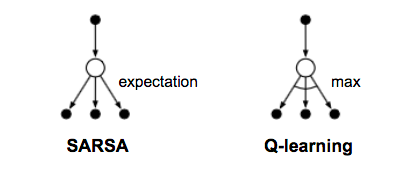
SARSA(State–Action–Reward–State–Action)是TD差分法应用在\(Q(s,a)\)一个基本算法,并且SARSA可以称为on-policy算法。
顺便解释很重要很容易混淆的概念,on-policy和off-policy
On-policy:使用目标策略中的确定性结果或样本来训练算法。
Off-policy:通过转移概率分布或者由不是经目标策略生成的而是由不同行为策略的生成的episodes来训练算法。
此外,从另一方面说,策略\(\pi(a|s)\)表示为状态\(s\)下到动作\(a\)的映射 on-policy算法表示使用相同的策略选择动作 来计算\(Q(s_t, a_t)\) 和TD target中\(Q(s_{t+1}, a_{t+1})\)。即在同一时刻我们 使用(following) 并且 改善(improving) 同一个(same) 策略。
为了更好理解Off-policy 我们引入行为策略(behavior policy) \(\mu(a|s)\),在所有时刻\(t\)的\(Q(s_t, a_t)\)中动作\(a_t \sim \mu(a|s)\)。在On-policy中,行为策略会是遵循的政并同时进行优化的策略。在 off-policy中有两个不同的策略\(\mu(a|s)\)行为策略\(\pi(a|s)\)和目标策略(target policy) 行为策略用来计算\(Q(s_t, a_t)\) 目标策略用来计算TD target中的\(Q(s_t, a_t)\)。
接着 回到SARSA算法。 SARSA指的是通过遵循序列\(\dots, S_t, A_t, R_{t+1}, S_{t+1}, A_{t+1}, \dots\)来更新Q值的过程。这个想法和Generalized Policy Iteration(GPI)相同。
- 在时刻\(t\), 从状态\(S_t\)开始,根据此时\(Q\)值选择一个动作\(A_t = \arg\max_{a \in \mathcal{A}} Q(S_t, a)\)。 选择策略通常是用\(\varepsilon-greedy\)策略。
- 当得到\(A_t\)后,我们可以得到即时回报\(R_{t+1}\)和下一状态\(S_{t+1}\)
- 接下来和步骤1一样选择\(S_{t+1}\)状态的动作:\(A_{t+1} = \arg\max_{a \in \mathcal{A}} Q(S_{t+1}, a)\)
- 根据之前的公式更新行为价值函数(action-value function): \(Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \alpha (R_{t+1} + \gamma Q(S_{t+1}, A_{t+1}) - Q(S_t, A_t))\)
- \(t=t+1\),并跳回步骤1.
On-policy:在SARSA的每一次更新时,我们在步骤一和三选择动作都依当前相同策略。
Q-Learning: Off-policy TD control
Q-Learning[Watkins & Dayan, 1992]的发展可以说是强化学习早期的一个突破进展。
- 在时刻\(t\), 从状态\(S_t\)开始,根据此时\(Q\)值选择一个动作\(A_t = \arg\max_{a \in \mathcal{A}} Q(S_t, a)\)。 选择策略通常是用\(\varepsilon-greedy\)策略。
- 当得到\(A_t\)后,我们可以得到即时回报\(R_{t+1}\)和下一状态\(S_{t+1}\)
- 更新行为价值函数(action-value function): \(Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \alpha (R_{t+1} + \gamma \max_{a' \in \mathcal{A}} Q(S_{t+1}, a') - Q(S_t, A_t))\)
- \(t=t+1\),并跳回步骤1.
DQN(Deep Q-Network)
到了本节的重点DQN,理论上来说我们可以通过Q-Learning来最小化\(Q_{\*}(.)\)来优化所有状态下的状态行为对,比如一个巨大的表,但是当状态行为空间太大的时候,计算就变得不可能。因此人们使用函数来估计Q值,这种方法叫做函数近似(function approximation),比如我们使用\(\theta\)参数下的函数来计算Q值,我们可以吧Q值函数表示为\(Q(s,a;\theta)\)。同时当我们观察更新规则,当\(Q(s, a)\)于TD-target值相同时,更新就会停止。也就是说\(Q(s, a)\)此时收敛到了真值,我们的目标也就达到了。
所以说目标:是为了最小化TD-target和\(Q(s,a)\)之间的差异,可由平方误差损失函数表示,求解最小化这个损失函数可以由梯度下降算法来解决。
\[\mathcal{L}(\theta) = \mathbb{E}_ {(s, a, r, s')\sim U(D)} \Big[ \big( \underbrace{r + \gamma \max_{a'} Q(s', a'; \theta^{-})}_{TD-target} - Q(s, a; \theta) \big)^2 \Big]\]
其中\(U(D)\)表示经验回放里的均匀分布,\(\theta^{-}\)是frozen target Q-network 参数(后面再介绍)
但是,当Q-Learning 与非线性Q值函数近似和bootstrapping 结合后会使算法变得不稳定和发散(divergence)。
Deep-Q-Network(“DQN”;Mnih et al. 2015)通过多种创新机制,极大地改善和稳定Q-learning的训练过程
Target-Networ;Q-Network
注意:在当前状态\(s\)下, Q-Network 计算动作-价值\(Q(s,a)\),同时Target-Network通过下一状态\(s'\)来计算TD-target里的\(Q(s',a')\)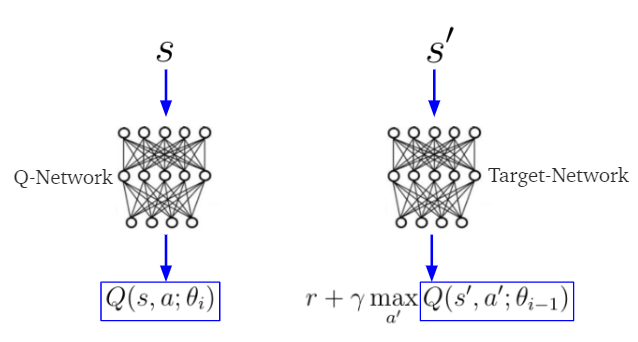
实验证明,同时使用两个不同神经网络来计算TD-target和\(Q(s,a)\)模型会有更好的稳定性。
Exploration/Exploitation
关于采取什么行动的决策涉及一个基本选择: * Exploration: 探索新的道路,获取更多的信息 * Exploitation: 基于现有信息做最好的决策。
对于Exploitation来说,智能体基于行为策略\(\mu\)来选择最可能执行的动作。但是会导致一个问题,万一存在另一个动作可以导致一个更好的结果(长期来看)。现有的情况下,我们只会利用策略,而不做其他的探索。
\(\epsilon\)-Greedy通过允许智能体小概率的随机采取行动,这样算一种Exploration。通常\(\epsilon\)会随着训练过程而改变,比如下式: \[ \epsilon = \frac{1}{\sqrt{n+1}} \] n是迭代的次数。\(\epsilon\)的变化说明我们是想在训练开始时,探索更多的可能结果,而在训练的后期,使策略变得更加稳定。
Experience Replay
在过去,可以看出如果DQN模型应用了经验回放,会使得神经网络对TD-target和\(Q(S,a)\)的估计变得更加稳定。所有的episode steps \(e_t = (S_t, A_t, R_t, S_{t+1})\) 被存储在回放记录\(D_t = \{ e_1, \dots, e_t \}\)里,\(D_t\)有很多episodes的经验元组。在Q学习更新的时候,样本随机从回访记录里选取并一个样本可能多次使用。经验回放提升了数据的利用率,并且减轻了观测序列之间相关性带来的影响。而且使数据分布的变化更为平滑。
Periodically Updated Target
Q值对目标值定期进行优化,在每C(超参数)步中,作为一个优化目标Q-network被复制并且冻结。这种操作使训练可以克服短期振荡的影响,模型表现更加稳定。
Deep Q-Learning Pseudo Algorithm

DQN存在很多的扩展形式,比如Dueling DQN; Double DQN; Rainbow