StyleGAN
引言
- 最近做的项目,基本上是基于这个的。现在做的差不多,做一个记录。也算是一个总结。
StyleGAN
论文:arxiv, A Style-Based Generator Architecture for Generative Adversarial Networks
code: A Style-Based Generator Architecture for Generative Adversarial Networks
可以先看下StyleGAN具体的效果,由程序生成的照片的和真实世界拍摄的照片,仅凭肉眼是很难区分的。

StyleGAN 从题目可以看出 可以分为 Style 和 GAN,GAN 是2014一个非常好的工作,利用对抗学习的思想,由噪声生成有意义的图片,但 GAN也有许多的问题,比如模型不稳定,缺乏对生成图像的控制等。 为了解决图像不可控这一问题,StyleGAN 从风格迁移借鉴了AdaIN 的思路来控制图像生成的“style”。
模型结构
传统的GAN模型如下图左所示,而StyleGAN的模型结构如下图右侧所示,可以划分为两个重点,分别是
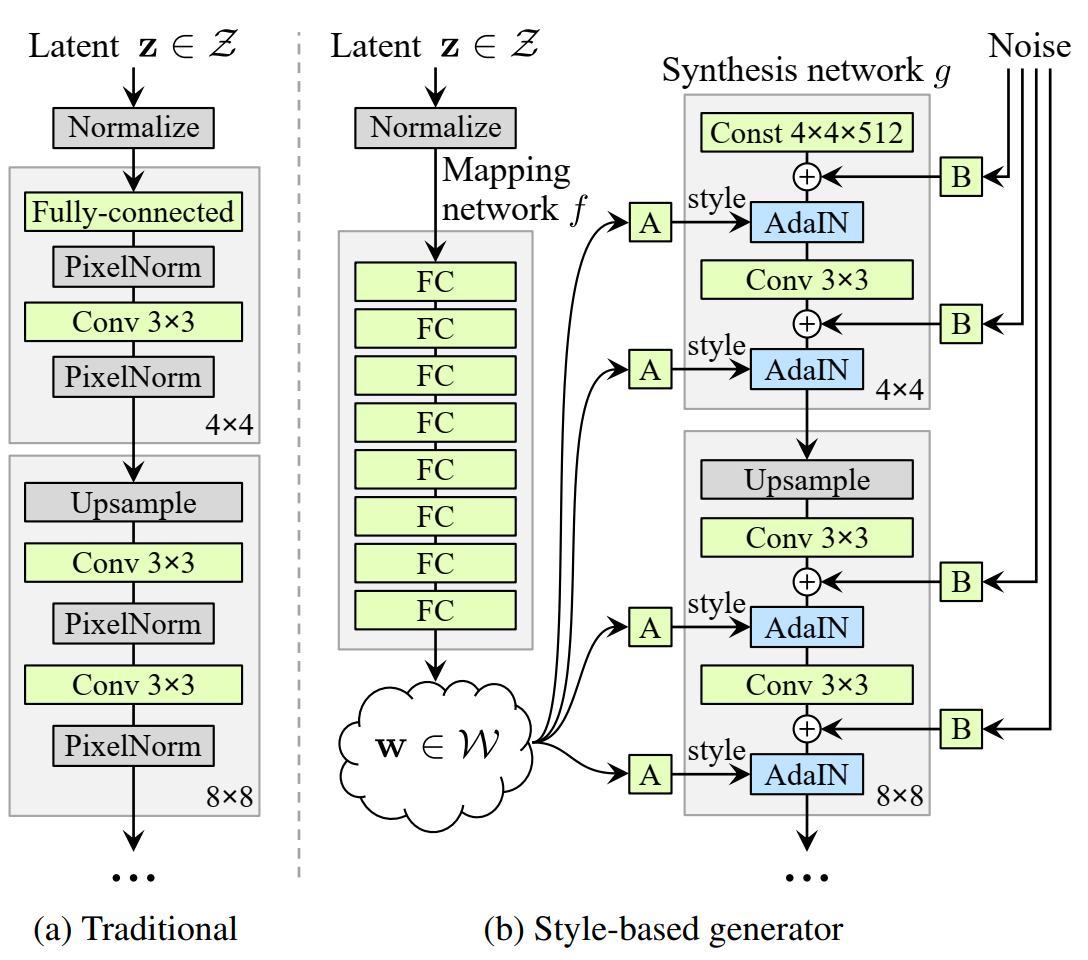
Mapping Network
通过高斯噪声 \(z\) 生成隐变量 \(w\) 的过程。通过全连接网络将高斯噪声映射到可以解耦的“style”空间里。作者给出这么做的原因是
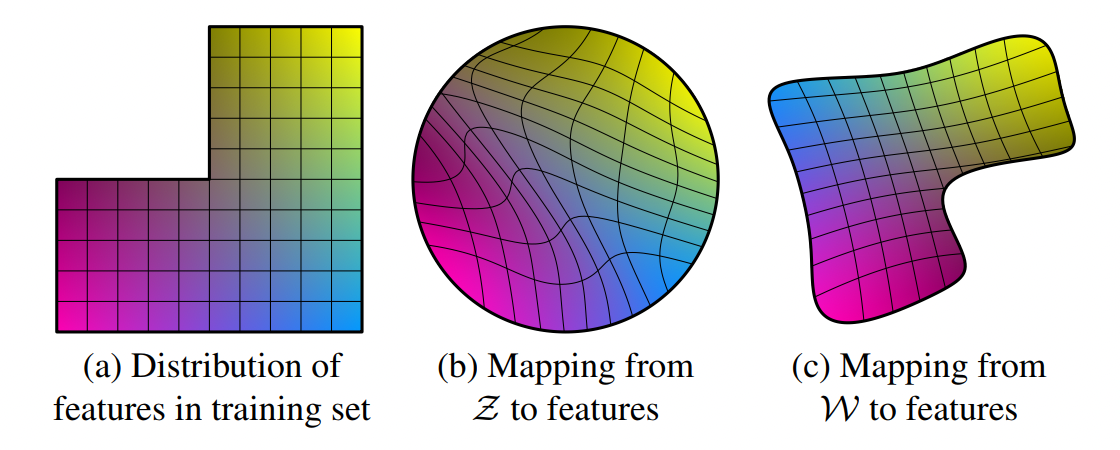
在现实空间中,假设图像的特征有两类,男子气概和长发,在数据集里同时具有男子气概和长发的样本大概率是空缺的。直接从 \(z\) 映射到特征空间是高度扭曲的,及在 \(z\) 上一个微小的扰动会导致映射的特征发生剧烈且不规则的变化。 而从 \(w\) 空间里到特征空间的映射,因为MLP的变换,使得和训练数据的分布比较吻合,更有利于模型的稳定。接着把 \(w\) 通过仿射变换分层送入生成网络 Synthesis Network。
Synthesis Network
\(w\) 通过仿射变换为风格向量 \(y = (y_{scale}, y_{bias})\) ,在生成网络Synthesis Network 中用于自适应实例归一化 AdaIN的输入.
Adaptive Instance Normalization (AdaIN)
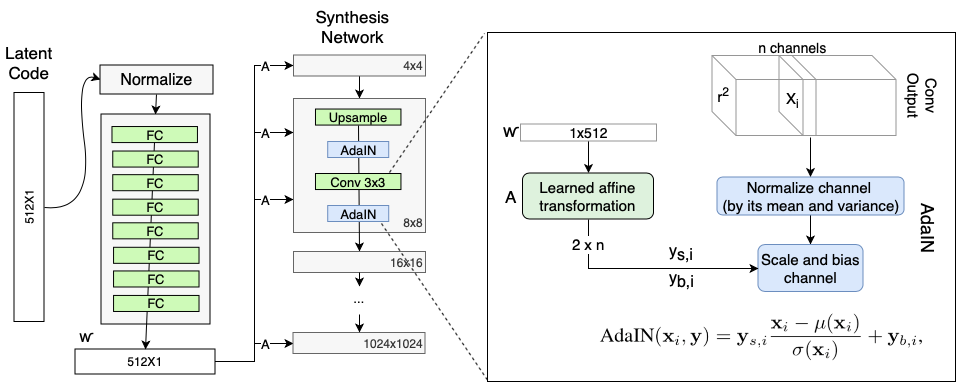
refer:图源
AdaIN 的运算定义为下式 \[ AdaIN(x_i, y_i) = y_{s,i}\frac{x_i - \mu(x_i)}{\sigma(x_i)} + y_{b,i} \]
- 其中卷积层每个通道的输出都进行归一化确保AdaIN操作可以到的预期的结果
- 通过风格向量 \(y\) 来定义每个卷积层的权重。
改变传统输入
传统的GAN的输入是随机输入, 而StyleGAN认为,图像的表现是由 \(w\) 和 AdaIN 控制的,所以可以将传统的随机输入改变成为常量输入,并认为这样可以让网络的学习结果与 \(w\) 更有相关性,而不依赖输入。
Stochastic variation 随机噪声
人像中有许多细粒度随机变化的特征,例如头发细节,面部斑点,皱纹等,这些细节显得人像更为逼真和多样。传统的GAN 通过在输入向量中增加噪声来影响这种变换,但由于是在输入向量中就插入,导致图像最后生成的其他特征也发生期望之外的变化。本文中通过在每层卷积后添加噪声来解决。
Style mixing 风格混合
通过对不同风格的照片映射到隐空间 \(w\) 中,选取不同层插入从不同风格引入的风格向量,这种特性使得生成的照片在不同粒度具有不同风格。 比如从A中学习到人像的脸型,从B中学习到眉毛和眼睛。
作者将18层划分为
- \(4^2 - 8^2\) Coarse styles
- \(16^2 - 32^2\) Middle styles
- \(64^2-1024^2\) Fine styles.
Other
还有一些其他值得学习的地方
Perceptual path length
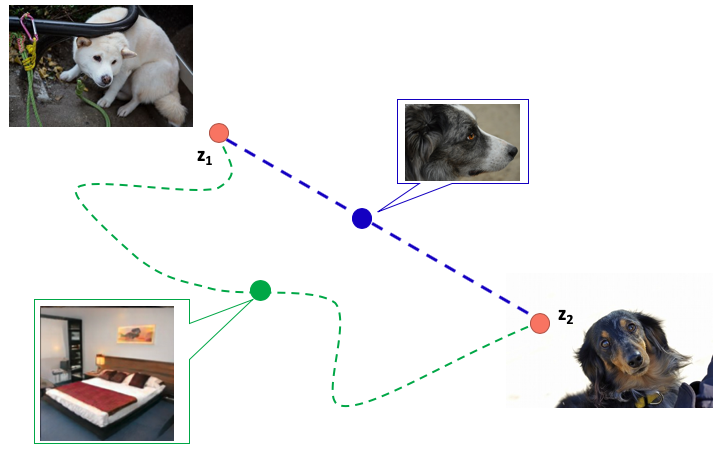
感知距离损失,当特征充分解耦后,我们假设从图像A到图像B的组合投影在隐空间上,应该是在A,B连线内, 图像变换是连贯的,而Perceptual path length就是用来表示这种指标,判断生成器是否选择了合适的变换“路线” \[ l_w = \mathbb{E}[\frac{1}{\epsilon^2}d(g(lerp(f(z_1),f(z_2);t)),g(lerp(f(z_1),f(z_2);t+\epsilon)))] \] d:判别器
g:生成器
f:mapping Network
\(f(z)\) :由z通过mapping Network 到 w
Lerp: linear interpolation 线性插值
通过预训练好的vgg16模型来判断图片之间的变化距离,如果从 \(t\) 改变 \(\epsilon\) 导致图像的变换很大,说明远离我们需要的的变换路径,感知距离越小,说明我们图片隐空间上变换就会越平滑。
Truncation in \(w\)
显然因为训练数据量的问题,大部分的生成空间都是没有被充分训练的,当在这种情况下是无法生成想要的图片,为了避免这种情况,StyleGAN,通过截断w,使得其不偏离平均w太远,这样生成图片围绕在充分训练的区域,更有利于高质量图片的生成。
后续会有StyleGAN2对它的问题再做些改进。
参考
https://towardsdatascience.com/explained-a-style-based-generator-architecture-for-gans-generating-and-tuning-realistic-6cb2be0f431
https://zhuanlan.zhihu.com/p/263554045